In 2024, a simple question broke the internet.
“How many R’s are in the word strawberry?”
The answer is three. Count them yourself: s-t-r-a-w-b-e-r-r-y. Three R’s. A seven-year-old gets this right immediately. ChatGPT — the most sophisticated AI system in the world at the time — confidently answered: two.
Screenshots went viral. Jokes flooded social media. Tech commentators wrote triumphant pieces about AI being overrated. And millions of people walked away with a vague sense that AI was somehow fundamentally broken or dishonest.
None of those reactions were quite right. The real explanation is more interesting than “AI is dumb” — and understanding it properly changes how you think about what AI can and cannot do. Not just for strawberries, but for an entire category of tasks that trip up every major AI system built the same way.
This is that explanation.
First — Try the Experiment Yourself Right Now
Before reading further, open ChatGPT or any AI assistant you have access to and ask it this exact question: “How many times does the letter R appear in the word strawberry?”
Depending on which model you use and when you are reading this, you might get two or three. If you get three, try: “How many R’s in blueberry?” Or: “Count the letter E in the word temperature.” Or: “How many times does the letter S appear in the word Mississippi?”
The specific word matters less than the pattern. AI systems that process language as tokens — which is most of them — will occasionally get these wrong in ways that seem bizarre for a system that can write complex code, explain quantum physics, and hold a nuanced argument across twenty exchanges.
The question worth asking is not “how did it get this wrong” but “why does this specific type of task expose something that complex reasoning tasks do not?”
What Your Brain Does That AI Does Not
When you read the word strawberry, something happens in your brain that feels automatic and invisible: you see the individual letters. S. T. R. A. W. B. E. R. R. Y. Each letter is a discrete unit. Counting how many R’s appear is simply a matter of scanning through those discrete units and tallying.
You have been doing this since you learned to read. It feels effortless. It is so basic that being asked to explain how you do it feels like being asked to explain how you walk.
Now here is the important thing to understand about AI language models: they do not read words the way you do.
They do not see individual letters. They do not process S, then T, then R, then A. They have never processed text that way, at any point in their development. The entire architecture of how they understand language is built on a different unit entirely — something called a token.
To understand why ChatGPT got strawberry wrong, you need to understand what a token is and why language models use them instead of letters.
What is a Token? The Real Building Block of AI Language
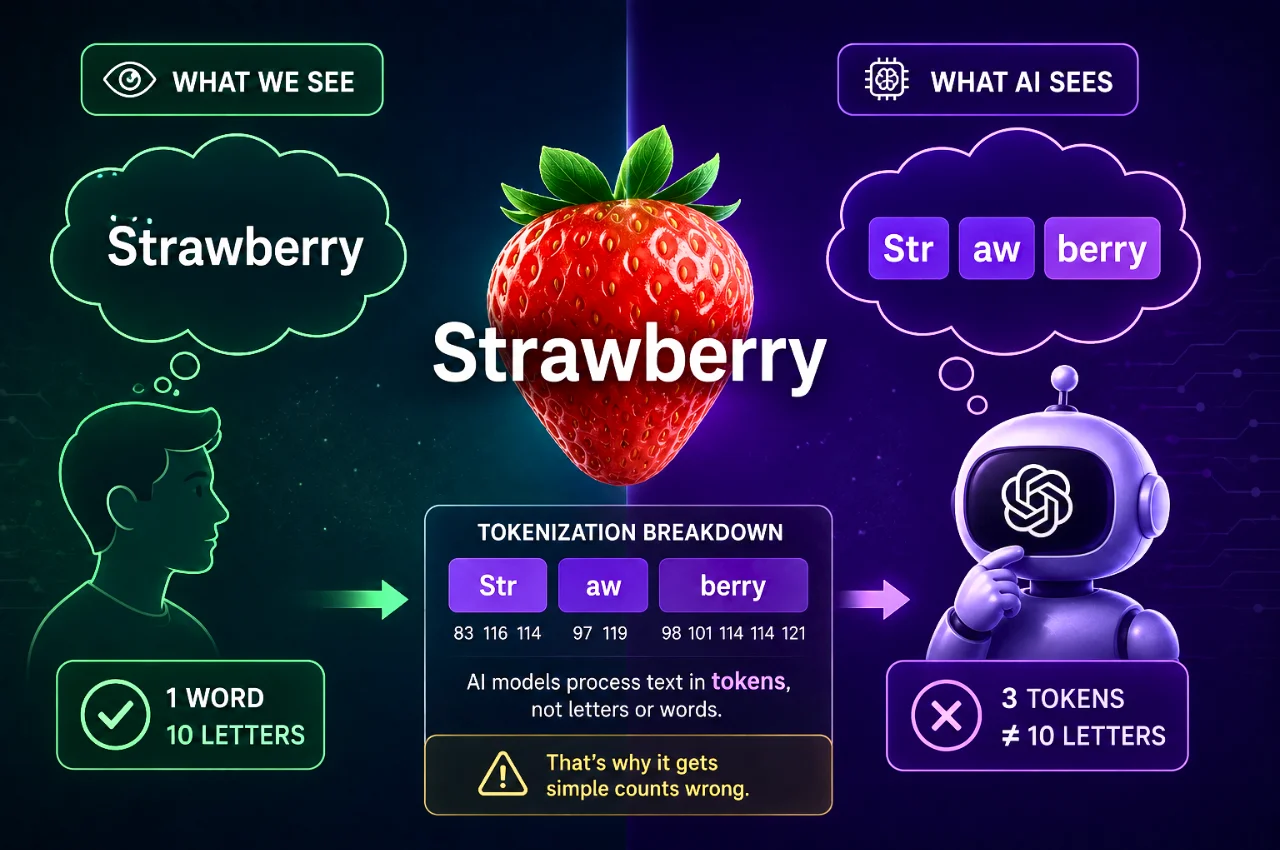
A token is not a letter. It is not always a word either. A token is a chunk of text — sometimes a whole word, sometimes part of a word, sometimes a punctuation mark and a space together — that a language model treats as its basic unit of processing.
Think of it like this. Imagine you were learning to read, but instead of being taught one letter at a time, you were handed flash cards with common word-chunks on them. One card says “ing.” Another says “tion.” Another says “pre.” Another says “berry.” You learn to recognize these chunks as complete units. When you encounter the word “running,” you see “run” and “ning” rather than seven individual letters.
This is closer to how AI language models process text. They use a system called tokenization — specifically a technique called Byte Pair Encoding, or BPE — that breaks text into the most statistically efficient chunks. Common words become single tokens. Common word-parts become single tokens. Less common words get split into multiple tokens.
The tokenization is not random. It is based on what patterns appear most frequently in the training data. Words and word-parts that appear together constantly get merged into single tokens because that compression is computationally efficient.
What Happens to Strawberry Specifically
Here is where it gets concrete. When you type the word “strawberry” into a system using OpenAI’s tokenizer, it does not see ten letters. It sees three tokens:
st — raw — berry
These three chunks are what the model actually processes. Not individual characters. Not a letter-by-letter scan. Three tokens, each treated as an indivisible unit.
Now ask yourself: how many of those tokens contain the letter R?
“st” — no R.
“raw” — one R.
“berry” — R and R. But wait. “Berry” is a single token. As far as the model is concerned, it is one indivisible thing, the same way “ing” is one thing to someone reading via flash cards. The two R’s inside “berry” are compressed inside a single unit that the model cannot look inside of.
So when you ask the model to count R’s, it is not scanning letters. It is scanning tokens. It finds R in “raw.” It finds the single token “berry” which contains the letter somewhere but the model cannot decompose it into individual characters to count them precisely. The result: two R’s instead of three.
The error is not the model being unintelligent. It is the model being asked to perform a task — individual character-level counting — at a level of granularity that its fundamental architecture does not operate at.
Why Tokenization Exists — The Real Reason
At this point a reasonable question is: why would you build AI this way? If tokenization causes this problem, why not just process letter by letter?
The answer is scale.
Language models are trained on trillions of words. The computational cost of processing text scales with the number of units you process. If you process letter by letter, every word is six to twelve units. If you process by tokens — where common words are single units — you process the same text in far fewer steps. Training becomes faster by orders of magnitude. Serving responses becomes cheaper. The entire economics of large-scale AI become tractable.
The Byte Pair Encoding algorithm was not invented for AI. It was invented in 1994 for data compression — the same family of ideas as ZIP files. It was adapted for neural network language models by researchers at the University of Edinburgh in 2015, and it has been the dominant approach ever since because nobody has found something better at scale.
The strawberry problem is the cost you pay for that efficiency. It is not a bug in the usual sense. It is an architectural trade-off that delivers enormous benefits and creates a specific, predictable category of failure at the same time.
The April 2026 Controversy — Did OpenAI Just Hardcode the Fix?
On April 28, 2026, ChatGPT’s official account posted a tweet that many users interpreted as a landmark moment: the model now correctly identified three R’s in strawberry. The replies did not erupt in applause.
Android Police founder Artem Russakovskii was among the first to respond, claiming that OpenAI had simply hardcoded the fix — meaning someone had baked the specific correct answer to the specific strawberry question directly into the model’s behavior, without solving the underlying tokenization architecture that causes the error.
Users immediately began testing adjacent cases. Blueberry. Raspberry. The letter counting in Mississippi. Temperature. Other words where the same tokenization problem would logically produce the same type of error. Early results were not uniformly reassuring. Some adjacent cases still failed. Some passed. The pattern was inconsistent in the way you would expect from a targeted fix rather than a genuine architectural resolution.
OpenAI published no changelog. No formal acknowledgment of what changed or which model version was affected. The tweet was the only signal.
Whether the fix represents genuine progress or a specific patch for a specific famous example is something the AI research community continues to actively debate. What the research community largely agrees on is this: fixing the strawberry answer does not fix the underlying architecture. LLMs still process tokens, not letters. The category of failure that produced the strawberry problem still exists. The fix may have addressed the most famous single instance of it without touching the root cause.
How Other AI Models Handle This Differently
Here is something that genuinely surprised many people who followed the strawberry story: Claude, Gemini, Grok, Perplexity, and several other AI systems gave the correct answer of three R’s even when ChatGPT was giving two.
This seems paradoxical. If the problem is tokenization, and all AI language models use tokenization, why do some get it right and others do not?
The answer is that different systems use different tokenization methods. Claude and Gemini use tokenizers that happen to split “strawberry” differently than OpenAI’s tokenizer does. Some systems split it into chunks that each contain one R, making the counting easier. Some reasoning models — including OpenAI’s own o3 and similar architectures — use a multi-step approach where they decompose words into characters explicitly before performing counting tasks.
The deeper point is that passing the strawberry test does not mean a model has solved letter-level reasoning in general. It means that specific word tokenizes in a way that does not create the specific failure. Different words, different tokenizers, different results. The architecture is the same. The specific outcome varies by word and by model.
A May 2026 research paper from the TeacherAndTask publication made this precise: the 2024 to 2026 generation of reasoning models like o3 and Claude Extended Thinking usually get the strawberry question right, but through a different mechanism — they have learned to decompose words into characters before counting, a behavior trained into them specifically, not a fundamental change in how tokenization works.
What Else Does This Explain — The Wider Pattern
Once you understand tokenization, a whole category of AI behavior that seemed random or stupid suddenly makes sense.
Arithmetic errors on certain numbers happen for the same reason. Numbers are also tokenized, and multi-digit numbers can split in ways that make precise calculation difficult at the character level. AI systems are generally much better at arithmetic when using a code interpreter — a tool that executes actual mathematics — than when reasoning through numbers purely in text.
Spelling errors on unusual words follow the same pattern. A word that tokenizes into unusual chunks is harder for the model to reconstruct character by character. The model knows the concept of the word but may not reliably reproduce its exact letter sequence.
Rhyming and wordplay puzzles that require tracking individual letters or syllables trip up language models more than tasks requiring broad reasoning. Tokenization is why.
Anagrams, palindromes, and letter scrambles are all tasks that require character-level processing. Language models built on subword tokens perform these inconsistently because the architecture is not built for that level of granularity.
None of this means the models are failing at language. They are succeeding at language in the sense that language is almost entirely about meaning, not letter sequences. The models were built and optimized for meaning. Letter-level tasks are a specific edge case that sits below the level the models were designed to operate at.
The Deeper Point This Reveals About AI
The strawberry story is genuinely instructive, not because it proves AI is overhyped, but because it reveals something important about what AI language models actually are and are not.
They are not reading the way you read. They are not thinking the way you think. They are not processing language at the level of individual symbols. They are processing patterns in high-dimensional statistical spaces, and they do it with extraordinary capability for most of what language is actually used for — reasoning, explanation, generation, translation, summarization, conversation.
The failure on letter counting is revealing precisely because it is such a basic task by human standards. A task that seems trivially simple to you is difficult for AI because your version of simple and AI’s version of simple do not overlap perfectly. Your brain is optimized for things that were useful for human survival and communication. AI systems are optimized for patterns in text. Those optimizations overlap substantially but not completely.
Understanding where they do not overlap makes you a much smarter user of AI tools. You stop expecting AI to perform character-level tasks reliably. You stop being surprised when it fails at arithmetic without a calculator. And you stop mistaking those specific failures for evidence of general incompetence in the areas where the architecture genuinely excels.
A Simple Test You Can Run Right Now
To make this concrete, try these prompts yourself and observe the results. They all probe the same tokenization-related limitation in different ways.
Ask any AI: “How many vowels are in the word ‘cryptography’?” Then ask it to spell the word out letter by letter first, then count. Notice whether counting after spelling gives a more reliable answer than counting directly.
Ask: “What is the seventh letter in the word ‘temperature’?” Compared to: “Spell out temperature letter by letter, then tell me which letter is seventh.”
Ask: “Does the word ‘level’ read the same backwards?” Then try: “Is the word ‘racecar’ a palindrome?”
In each case, prompts that force the model to decompose a word into individual characters before performing the task tend to produce more accurate results than prompts that ask for the analysis directly. This is not a workaround to a bug. It is using the model in a way that accommodates the architecture.
Key Takeaway
ChatGPT getting strawberry wrong is not evidence that AI is dumb, broken, or dishonest. It is evidence that AI language models process text as tokens — statistically efficient chunks — rather than individual letters. That architectural choice makes large-scale language modeling computationally feasible and is responsible for everything impressive that these systems can do. It also creates a predictable category of failure at the character level.
The strawberry problem is the most memorable example of a real, architectural limitation. Understanding why it happens does not diminish your sense of what AI can do — it sharpens it. You come away knowing not just that AI sometimes fails at letter counting, but exactly why, and exactly what class of tasks shares that same failure mode.
That understanding is more useful than the viral screenshot ever was.
Frequently Asked Questions
Has ChatGPT fixed the strawberry problem now?
In April 2026, ChatGPT’s official account posted that the model now correctly identifies three R’s in strawberry. However, AI researchers and users immediately raised concerns that the fix was hardcoded — meaning the specific answer to the specific famous example was patched directly — rather than representing a genuine architectural solution to character-level counting. Testing on adjacent words continued to show inconsistent results. The underlying tokenization architecture remains unchanged.
Do all AI models get the strawberry question wrong?
No. Different AI models use different tokenizers, and some split “strawberry” into chunks that make the R counting easier. Claude, Gemini, Grok, and Perplexity gave the correct answer of three R’s even when ChatGPT was giving two. However, this does not mean those models have solved character-level reasoning generally — it means their tokenizers happen to handle this specific word differently.
If I spell out a word letter by letter to ChatGPT, can it then count correctly?
Often yes. Forcing the model to see individual characters before performing a counting task bypasses the tokenization problem. When you write “s-t-r-a-w-b-e-r-r-y” with hyphens between each letter, the model has explicit access to the individual characters and can count more reliably. This is a practical workaround for this class of task.
Does tokenization affect anything else besides letter counting?
Yes — tokenization affects arithmetic on unusual numbers, spelling of rare words, palindrome and anagram detection, rhyme identification, and any task requiring precise character-level analysis. These are all tasks that sit below the level of granularity that token-based language models were designed to operate at.
Why was tokenization designed this way if it causes these problems?
Tokenization using Byte Pair Encoding was adopted because it makes training and running large language models computationally feasible. Processing individual letters would multiply the length of every text by five to ten times, dramatically increasing the computational cost of training and serving AI systems. The strawberry problem is the known cost of an architectural choice that enables everything else these systems can do.
Is this a problem that future AI will solve?
Possibly. Some newer reasoning models use multi-step approaches that explicitly decompose words into characters before analysis. Some researchers are exploring byte-level and character-level architectures that process text at finer granularity. But as of 2026, subword tokenization remains the dominant architecture because no alternative has matched it for overall language modeling quality at scale. The strawberry problem remains an active area of research rather than a solved one.
Final Thoughts
The word strawberry became famous in AI circles not because it exposed fraud or incompetence, but because it exposed the gap between what AI looks like from the outside and what it actually is on the inside.
From the outside, a system that can write a novel, explain general relativity, debug complex code, and hold a philosophical argument across an hour of conversation seems like it should trivially count three R’s in a common English word. The failure feels absurd.
From the inside, the failure makes complete sense. The system processes tokens. Tokens are not letters. Letter counting is not what it was built for. The surprise is not that it fails at letter counting occasionally — the surprise is that it succeeds at everything else.
That gap between outside appearance and inside architecture is worth understanding for anyone who uses AI regularly. It tells you what to trust, what to verify, and what to ask differently. It replaces the vague unease of “AI sometimes gets things wrong” with a specific, actionable understanding of exactly which types of tasks expose which architectural limitations.
The strawberry story is not about AI being stupid. It is about AI being different. And different, once you understand it properly, is far more interesting than stupid.