You type “best phone under 20000” into Google and it gives you exactly what you were looking for. You ask Siri “what is the weather tomorrow” and it answers correctly, even though you did not use any specific command syntax. You type a message in Hindi to Google Translate and it comes back in English — not word by word, but in natural, readable sentences. You send a voice note on WhatsApp and your phone transcribes it into text.
Every one of these things requires a computer to understand human language. Not keywords. Not commands. Actual language — with all its messiness, ambiguity, and context-dependence.
The technology that makes this possible is called Natural Language Processing, or NLP. It is one of the oldest and most fundamental branches of artificial intelligence, and it is so deeply embedded in the tools you use every day that most people have never stopped to wonder how it works.
This guide explains it — properly, in plain language, without assuming you have a computer science background.
What is Natural Language Processing?

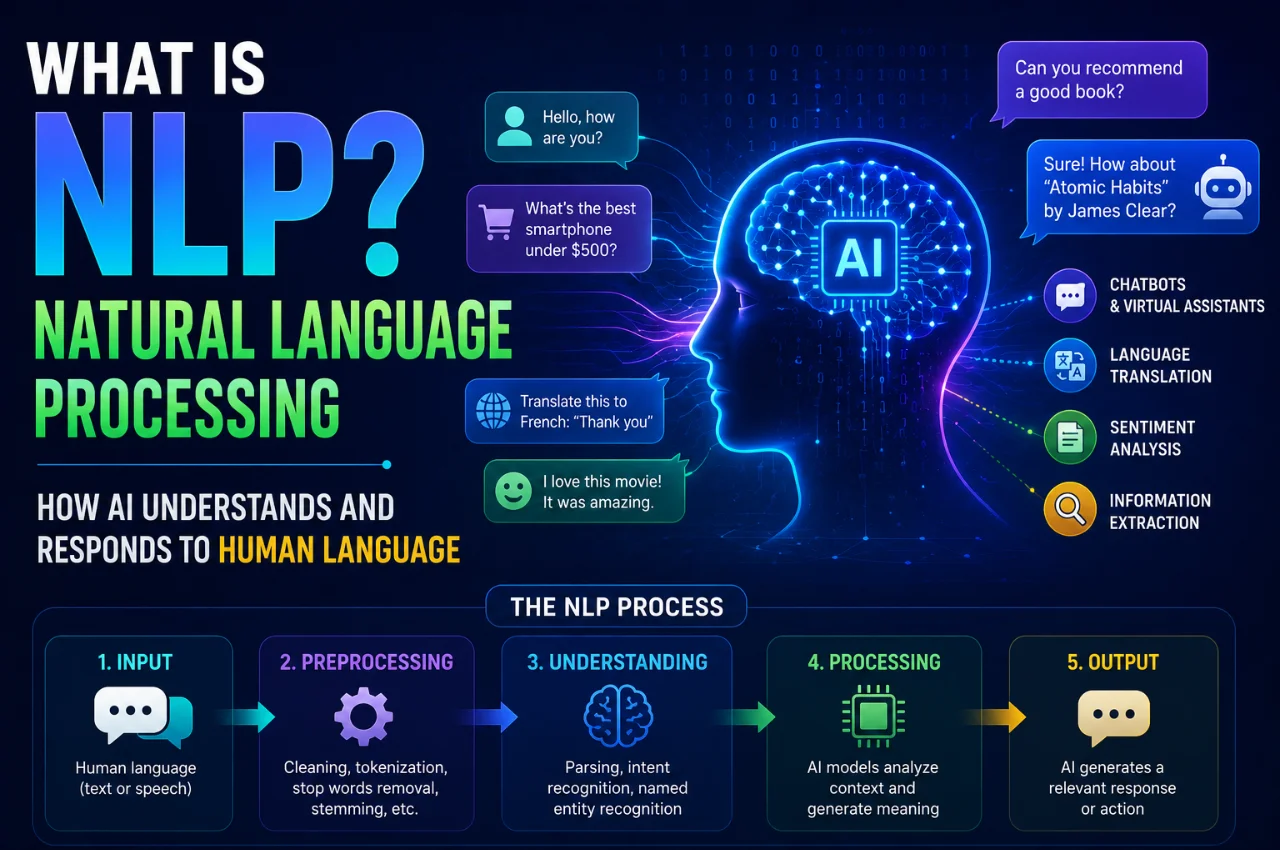
Natural Language Processing, abbreviated as NLP, is the branch of artificial intelligence that enables computers to read, understand, interpret, and generate human language — both written text and spoken speech.
The “natural” in the name is doing important work. Natural language is how humans actually communicate — the language of everyday conversation, writing, and speech. This is distinct from programming languages or formal command structures, which follow rigid, explicit rules. Natural language is fluid, context-dependent, full of ambiguity, and shaped by culture and history in ways that make it extraordinarily difficult for machines to handle.
For most of the history of computing, the only way to communicate with a computer was in the computer’s language — structured commands, precise syntax, no room for the kind of flexibility that characterizes how humans actually talk. NLP is the field dedicated to closing that gap — to making computers capable of understanding the language humans already use, rather than forcing humans to learn the language computers require.
When you ask your Google Assistant a question in conversational Hindi, and it understands what you meant and responds helpfully, that is NLP at work. When spam filters correctly identify an unsolicited email as junk, that is NLP. When Netflix recommends a show “because you watched something similar,” it used NLP to analyze the text of reviews, descriptions, and metadata. When your autocorrect catches a typo and suggests the right word, that is NLP.
It is everywhere. You just never needed to know what it was called.
Why is Understanding Human Language So Hard for Computers?
To appreciate what NLP actually does, it helps to understand why human language is genuinely difficult — not for you, because you learned it growing up and process it effortlessly, but for a machine that has no experience of the world and no intuition about meaning.
Consider the word “cool.” In the sentence “that jacket is cool,” it means fashionable. In “the temperature is cool,” it means mildly cold. In “cool, I will be there at five,” it means okay or understood. Same word, completely different meanings — and you knew which was which instantly because of context. A computer has to figure that out through analysis.
Consider the sentence “I saw the man on the hill with a telescope.” This single sentence has at least five different legitimate interpretations depending on who had the telescope, who was on the hill, and how the telescope was being used. Humans resolve this ambiguity using context and common sense. Computers do not have access to those automatic shortcuts.
Or consider sarcasm. “Oh great, another Monday.” The words are positive. The meaning is the opposite. No literal reading of that sentence reveals what it actually communicates. Understanding it requires recognizing a social convention that varies by culture, age, and context.
Human language is ambiguous, figurative, culturally specific, and deeply dependent on shared real-world knowledge that is difficult to formalize. Teaching a computer to handle all of that is the challenge that NLP has spent decades working on — and, in recent years, making genuinely remarkable progress toward solving.
A Brief History — How NLP Got Here
NLP is not new. Researchers have been working on it since the 1950s, and the history of the field is a story of different approaches, repeated frustrations, and eventually a breakthrough that changed everything.
The earliest NLP systems in the 1950s and 1960s used rule-based approaches. Researchers wrote explicit rules about grammar, syntax, and word relationships — if the sentence contains this pattern, it means that. These systems worked in narrow, controlled environments. They fell apart the moment they encountered real-world language, which constantly breaks the rules.
Through the 1970s and 1980s, researchers attempted more sophisticated linguistic analysis — parsing sentences into their grammatical components, building knowledge bases of word meanings and relationships. Progress was real but slow, and the systems remained fragile outside carefully constrained domains.
The statistical revolution of the 1990s changed the approach fundamentally. Rather than trying to write explicit rules about language, researchers began training statistical models on large amounts of real text — letting the patterns in actual language data guide the models’ behavior. This worked significantly better than hand-crafted rules and produced real improvements in machine translation, speech recognition, and text classification.
The deep learning revolution of the 2010s was the breakthrough that transformed NLP from a difficult, specialized research problem into the technology powering products used by billions of people. Neural networks trained on enormous amounts of text learned representations of language far richer than anything previous approaches had achieved.
The pivotal moment was 2017 — the same year we mentioned in other AI articles — when Google researchers published the paper introducing the Transformer architecture. Transformers were specifically designed to handle language by attending to the relationships between all words in a text simultaneously, rather than processing them sequentially. This allowed models to capture long-range dependencies and contextual nuances that previous approaches missed. The Transformer is the architecture that powers GPT, BERT, and every major language model in use today.
By 2022 and 2023, NLP had advanced to the point where systems like ChatGPT could hold extended conversations, write coherent essays, answer questions about complex documents, and generate code — all through natural language interaction. The gap between human language and machine understanding had never been smaller.
How Does NLP Actually Work? The Key Steps Explained Simply
When an NLP system processes a piece of text — say, a question you typed into a chatbot — it goes through several steps that transform your raw input into something the computer can work with, and eventually into an appropriate response.
The first step is tokenization. The text gets broken down into smaller units called tokens. These are not always full words — tokens can be whole words, parts of words, punctuation marks, or spaces, depending on the tokenization approach used. The sentence “I love Indian food” might become the tokens [“I”, “love”, “Indian”, “food”]. This gives the system discrete units to work with.
The second step is understanding language structure. The system analyzes grammatical relationships — which words are nouns, which are verbs, which words modify which others. This structural understanding helps the system grasp the basic meaning of the sentence before diving into deeper interpretation.
The third step is semantic understanding — figuring out what the words actually mean in context. This is where the deep learning models do their most impressive work. The word “bank” means something different in “river bank” versus “bank account.” The word “light” means different things in “a light meal,” “the light was on,” and “please light the candle.” Context-sensitive semantic understanding is what separates modern NLP from earlier keyword-matching approaches.
The fourth step is intent recognition. What does the person actually want? A question about “the best phone” has the intent of seeking a recommendation. A question about “how to transfer WhatsApp data” has the intent of getting step-by-step instructions. Correctly identifying intent is what allows AI assistants to give relevant responses rather than just parsing the literal words.
The fifth step, for systems that generate responses, is natural language generation. The model produces a response in natural language — grammatically correct, contextually appropriate, and helpful. This is the step where all the pattern learning from training data comes into play, as the model generates text that fits the context of the conversation.
The Core Tasks Within NLP
NLP is not one single thing — it is a collection of related tasks, each of which is a specific problem in language understanding or generation. Here are the most important ones explained simply.
Sentiment analysis determines whether a piece of text expresses a positive, negative, or neutral feeling. When you leave a product review on Amazon or a restaurant rating on Zomato, sentiment analysis tools process millions of similar reviews to give businesses insight into customer satisfaction. Political analysts use it to gauge public reaction to news events. Social media platforms use it to identify potentially harmful content.
Machine translation converts text from one language to another. Google Translate, Microsoft Translator, and DeepL are all NLP-powered translation systems. Modern neural translation approaches are dramatically better than older statistical approaches — they produce text that reads naturally rather than word-for-word substitutions that lose idiomatic meaning.
Named entity recognition identifies and classifies specific named things in text — people, organizations, locations, dates, amounts. When you search for news about “Tata Motors” and Google correctly identifies it as a company rather than just two random words, named entity recognition is involved.
Text summarization condenses long documents into shorter summaries while preserving the key information. Tools that summarize news articles, legal documents, research papers, or meeting transcripts use this NLP capability. It is one of the most practically useful applications of NLP for productivity.
Question answering enables systems to respond to factual questions based on a body of text. When you ask a virtual assistant a specific factual question and it gives you the right answer, question answering NLP is at work.
Speech recognition converts spoken audio into written text. The technology that powers voice search, voice-to-text on your phone keyboard, live captioning on video calls, and voice assistants like Alexa and Google Assistant all rely on NLP-based speech recognition.
Text classification assigns categories or labels to pieces of text. Email spam filters classify incoming emails as spam or not spam. Customer service tools classify incoming tickets by topic so they can be routed to the right team. News aggregators classify articles by topic for relevant recommendations.
Conversational AI enables systems to hold extended, multi-turn conversations — maintaining context across many exchanges rather than treating each message as isolated. ChatGPT, Google Gemini, and Claude are all built primarily on conversational NLP capabilities.
NLP in Your Everyday Life — You Use It Constantly
Knowing the technical definition of NLP is one thing. Seeing it in the specific tools and moments of daily life makes it real.
Google Search uses NLP to interpret your queries as questions with meaning rather than keyword strings to match. When you type “best restaurants near me open now,” Google does not search for pages containing exactly those words — it understands your intent and location context and retrieves relevant results. The AI Overviews that appear at the top of many search results are NLP-generated summaries.
Google Assistant and Siri use NLP for both speech recognition — converting your voice to text — and language understanding — figuring out what you are asking for. When you say “remind me to call Mummy when I get home,” the assistant correctly identifies this as a location-triggered reminder task and creates it accordingly. No command syntax, no formal structure — just your natural phrasing.
WhatsApp’s voice note transcription — available in several markets — uses speech recognition NLP to convert audio messages to readable text. The dictation feature on your phone keyboard does the same.
Gmail’s Smart Reply suggestions — the short responses suggested at the bottom of emails — are generated by NLP models that read the incoming email and generate contextually appropriate brief responses.
Google Translate handles not just word-for-word substitution but idiomatic expressions, sentence restructuring needed for grammatically correct output in the target language, and increasingly, contextual nuance. The quality has improved dramatically with neural NLP models compared to older approaches.
YouTube’s auto-generated captions use speech recognition NLP to transcribe spoken audio into text in real time. The accuracy has improved significantly in recent years, though it still struggles with accents, background noise, and technical terminology.
Customer service chatbots on e-commerce and banking websites use NLP to understand customer questions and provide relevant answers without human involvement. The difference between a chatbot that feels like talking to a wall and one that actually helps you lies almost entirely in the quality of its NLP.
Autocorrect and predictive text on your phone keyboard use NLP — specifically language models that predict the most probable next word given what you have typed and the context of the message you are composing.
NLP and Large Language Models — How They Relate
If you have read the other AI articles on this site, you know about large language models — the technology behind ChatGPT, Gemini, and Claude. Understanding how NLP and LLMs relate clears up a common source of confusion.
NLP is the broader field — the collection of techniques, tasks, and research dedicated to enabling computers to understand and generate human language.
Large language models are the current state-of-the-art approach to NLP. They are models trained on enormous amounts of text using the Transformer architecture, and they have proven capable of performing almost every NLP task at a level that surpasses all previous approaches. GPT-5, Gemini, and Claude are all large language models — which means they are the current cutting edge of NLP research made into products.
Before LLMs, each NLP task typically required its own specialized model — a separate system for translation, another for sentiment analysis, another for question answering. LLMs unified many of these tasks into a single model capable of performing all of them through natural language instruction. This unification is one of the most significant advances in the history of NLP.
The relationship is: NLP is the field, LLMs are the current dominant approach within that field.
NLP for Indian Languages — Why It Matters

India is a country of extraordinary linguistic diversity — over 22 official languages, hundreds of dialects, and over a billion people who are more comfortable in a language other than English. For NLP, this represents both a massive challenge and a massive opportunity.
Historically, NLP research and commercial development was heavily concentrated on English. The result was that the most capable AI tools were disproportionately useful for English speakers and significantly less capable in other languages — including Hindi, Tamil, Bengali, Telugu, Marathi, and other major Indian languages.
This is changing. Google has invested significantly in multilingual NLP models that cover Indian languages. Meta’s language model research explicitly prioritized low-resource language coverage. Microsoft’s language models include Indian language support. And Indian institutions — IITs, IIITs, and organizations like AI4Bharat — are specifically working on NLP tools and datasets for Indian languages.
The practical impact is significant. Government services accessible in regional languages. Healthcare information available to people who do not read English. Educational content in the language a student is most comfortable in. Agricultural advice delivered in the farmer’s native tongue. These are not abstractions — they are real improvements in access to information that NLP makes possible for populations that have historically been underserved by digital tools.
AI4Bharat’s IndicBERT and IndicTrans models represent India-specific NLP research that is producing capable language models for languages like Hindi, Bengali, Tamil, and Telugu that improve the quality of translation, speech recognition, and text understanding for hundreds of millions of people.
The Limitations of NLP — What AI Still Cannot Fully Do
As capable as modern NLP has become, it is worth being honest about where it still struggles.
True understanding remains an open question. When ChatGPT answers a complex question brilliantly, is it understanding the question in any meaningful sense, or is it producing statistically appropriate text that looks like understanding? Most researchers believe current NLP systems perform sophisticated pattern matching rather than genuine comprehension. They can generate perfectly appropriate responses without understanding them the way a human does.
Ambiguity at the level of common sense is still difficult. Humans bring enormous real-world knowledge to language interpretation — knowledge about physics, social norms, cause and effect, and thousands of other things. NLP models trained on text alone are missing a lot of this grounding. They handle most language well but can fail unexpectedly on sentences that require common sense reasoning.
Languages with limited training data remain under-served. While major world languages have benefited enormously from NLP advances, thousands of smaller languages lack the training data needed to build capable models. The digital divide in NLP capability follows the digital divide more broadly.
Sarcasm, humor, and culturally specific references remain genuinely difficult. The more a piece of language relies on shared cultural context, timing, tone of voice, or implicit knowledge, the harder it is for NLP systems to handle correctly.
Bias in training data creates bias in models. NLP models learn from text written by humans, which reflects the biases present in human communication. Sentiment analysis tools can rate identical text differently based on the apparent identity of the speaker. Translation models can make gendered assumptions. These biases are real, consequential, and actively being researched and addressed.
Key Takeaway
Natural language processing is the technology that allows computers to work with human language — to read it, understand it, analyze it, and generate it. It is the reason your Google search returns relevant results from a conversational query. It is the reason your voice assistant understands casual speech. It is why Google Translate produces readable text rather than mechanical substitutions. It is the foundational technology that makes every AI chatbot possible.
NLP has gone through decades of development — from rigid rule-based systems to statistical models to the deep learning revolution that made modern large language models possible. The result is technology that, while far from perfect, handles the complexity of human language with a capability that would have seemed impossible thirty years ago.
Understanding NLP means understanding something important about the AI tools that are increasingly central to daily life. When you know how these systems process and interpret language, you use them more effectively, recognize their limitations more clearly, and think more critically about how they shape the information you receive.
Frequently Asked Questions
Is NLP the same as AI?
NLP is a branch of artificial intelligence — a specific subfield focused on enabling computers to understand and generate human language. AI is the broader field covering all techniques that enable intelligent machine behavior. NLP is one important type of AI, alongside computer vision, robotics, and other specializations.
How is NLP different from machine learning?
Machine learning is a general approach to building AI systems that learn from data. NLP is a specific application domain — the application of machine learning (and other techniques) to language. Most modern NLP systems use machine learning as their core approach, particularly deep learning. The relationship is similar to how “cooking” is a general skill and “baking bread” is a specific application of that skill.
Can NLP understand Indian languages well?
Modern NLP handles major Indian languages — Hindi, Bengali, Tamil, Telugu, Marathi — significantly better than it did five years ago, thanks to multilingual model training and specific research initiatives like AI4Bharat. However, the capability gap between English and most Indian languages remains real. Regional dialects, code-switching (mixing languages mid-sentence as many Indian speakers naturally do), and languages with less digital text available still present significant challenges.
What is the difference between NLP and speech recognition?
Speech recognition is one specific task within NLP — the task of converting spoken audio into written text. NLP is the broader field that includes speech recognition as well as text understanding, translation, summarization, sentiment analysis, question answering, and many other language-related tasks. Speech recognition converts voice to text; NLP then makes sense of that text.
Is NLP responsible for ChatGPT?
ChatGPT is built on a large language model — which is the current state-of-the-art approach to NLP. So yes, NLP is the field that produced the research and techniques that make ChatGPT possible. GPT-4 and GPT-5 are large language models trained using NLP methods — specifically the Transformer architecture and extensive training on human-generated text.
Will computers ever truly understand language the way humans do?
This is one of the most debated questions in AI research. Current NLP systems produce outputs that demonstrate impressive language capability, but most researchers believe genuine human-like understanding — grounded in embodied experience, common sense, and consciousness — remains a distant or potentially impossible goal for current AI architectures. What NLP systems do is perform sophisticated pattern recognition and generation that produces useful, often impressive results without necessarily constituting understanding in the philosophical sense.
Final Thoughts
Natural language processing is one of those technologies that has been quietly transforming daily life for years while staying almost entirely invisible. Every search query, every autocorrect, every voice command, every translation, every chatbot response — all of it runs on NLP.
The recent explosion in large language model capabilities has brought NLP to a level of performance that genuinely surprises people when they encounter it. The AI that can write an essay, answer a complex question, summarize a document, or hold an extended conversation did not appear from nowhere — it emerged from decades of NLP research, culminating in the Transformer architecture and the scale of training that modern computational resources make possible.
Understanding NLP will not make you a better programmer or researcher. But it will make you a clearer thinker about AI — about what these systems are actually doing when they seem to understand you, what they are genuinely good at, where they fall short, and why the future of computing looks increasingly like a conversation.